Welcome to my personal website. I use this space to share some of my thoughts and software that I write in my free time. Sometimes I also publish photos. If you want to get in touch please use LinkedIn or Mastodon.
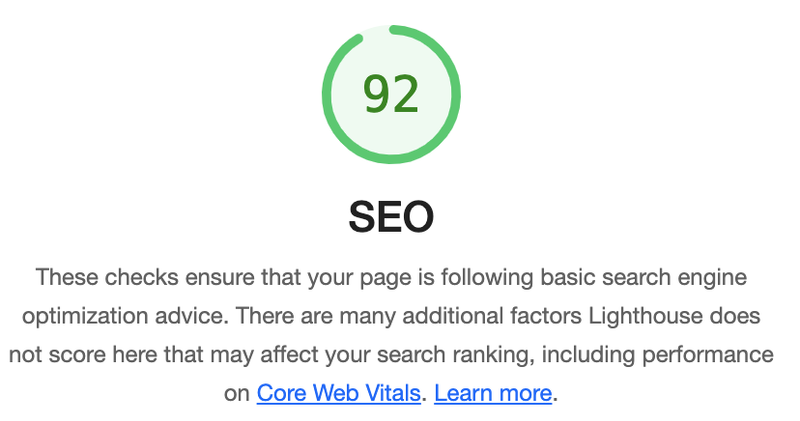
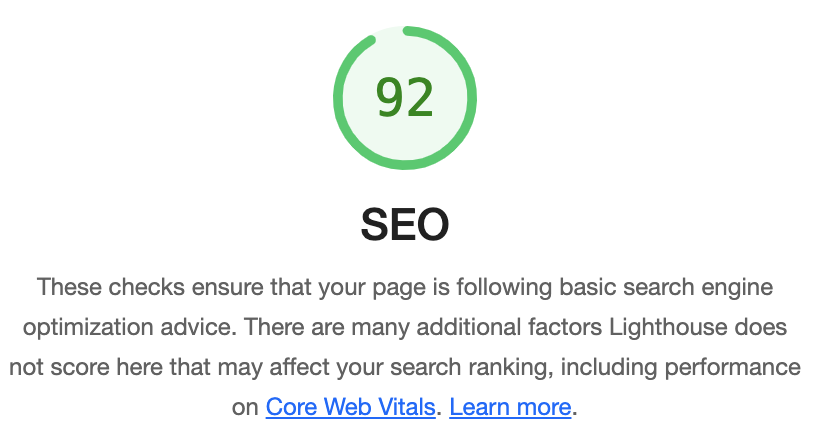
As the final step in this very small series I tried improving the SEO (search engine optimization) score for my start page. I started out with a good score of 92. As usual, my goal was 100.
Continuing from before, I wanted to improve the accessibility on this website as much as possible. The initial Lighthouse run gave me a score of around 82, which is not too bad, but I definitely wanted to improve it.
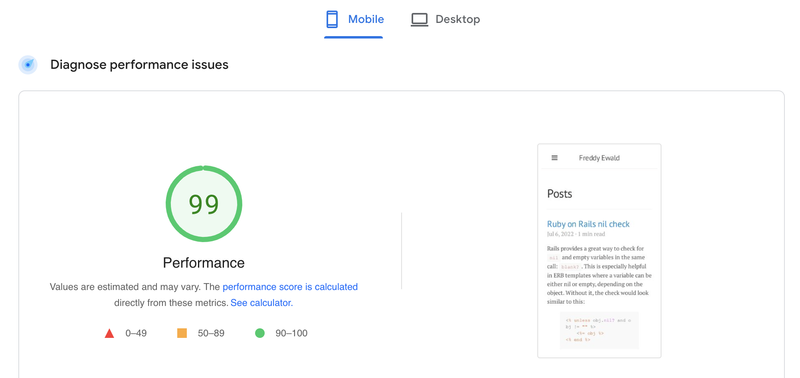
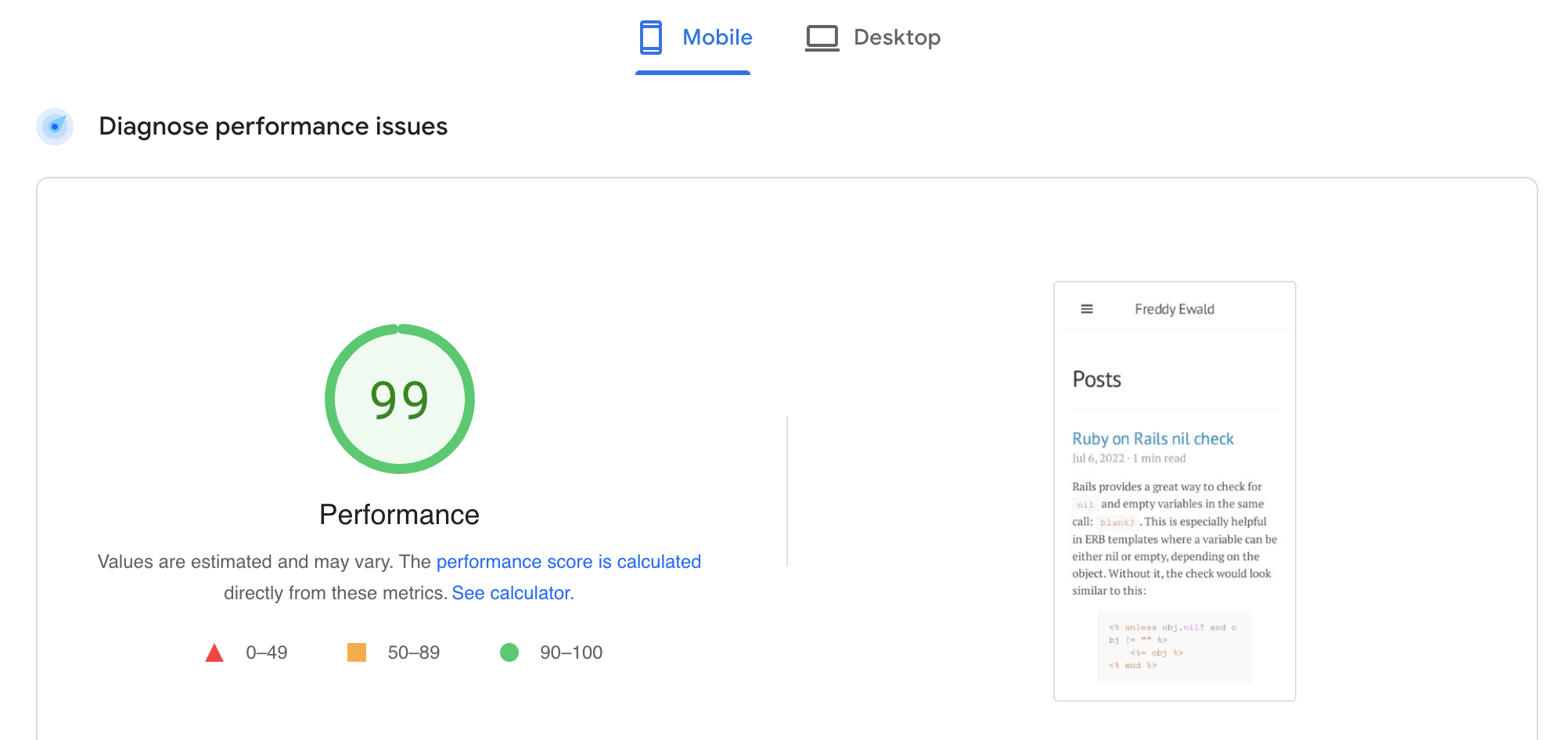
One important thing for a good user experience is a fast website. Google offers the free tool Page Speed Insights. Running it initially on my website I already have a score of 99, which is pretty good. In the past I already spent a fair amount of time optimizing the bigger problems.
I looked at the tips to improve the page speed even further. There are four things that Google considers currently in need of improvement on this page.
Rails provides a great way to check for nil and empty variables in the same call: blank?. This is especially helpful in ERB templates where a variable can be either nil or empty, depending on the object. Without it, the check would look similar to this:
<% unless obj.nil?andobj!=""%><%= obj %>
<% end %>
This is quite cumbersome and easy to forget. With blank?, this can be simplified to:
<% unless obj.blank?%>
<%= obj %><% end %>
For the following values blank? returns true and false respectively: