Welcome to my personal website. I use this space to share some of my thoughts and software that I write in my free time. Sometimes I also publish photos. If you want to get in touch please use LinkedIn or Mastodon.
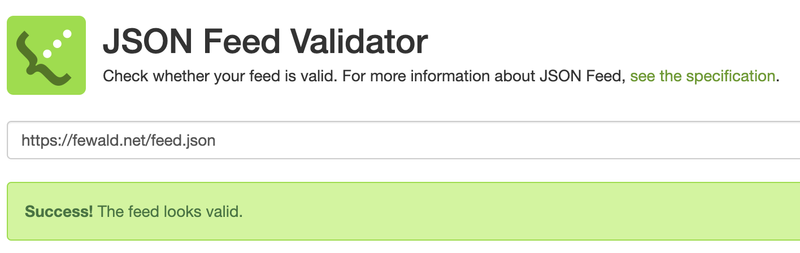
I finally followed through with my plan from 2017 to install JSONFeed for this blog.
Although I haven’t seen any breakthrough of this as a technology, I’ll keep it running next to the XML feed and will monitor all requests. This feed is compliant to the standard.
To get it to work, I had to adjust my template a little bit and also use jsonify from the liquid template language. Overall, it was easier to get an XML feed to work as JSON is very picky about escaping of double quotes and other special HTML characters. My template for Jekyll is saved as feed.json and looks as follows:
Probably not so much, or at least less than you might think.
We often need to store dates and times in a database and retrieve them later. I have seen people choosing to store those in the highest precision available. For example, in Python the precision for a datetime object is microseconds. That is one millionth of a second!
For a lot of use cases, this kind of precision is not needed. For many
cases, second precision is enough. Examples for use-cases that probably don’t need the highest precision are:
Blog posts
Comments
Social networks
Audit logs
Furthermore, it makes sense to use the same precision in your code as
in your database. By doing so, you get the exact same date and time when you save an object to the database and when you retrieve it later. This is especially important in tests where exact equality is tested.
One example is MySQL which has the DATETIME(3) type where the number denotes the sub-second precision. Defining the precision explicitly makes it not only more predictable in your code, it also avoid wasting space.
As usual, it depends on the use case. It does make sense to think a little bit about the precision to avoid problems later in the development process.
I was looking for an easy way to create new jekyll posts via command line and found the plugin Jekyll compose. I am very late to the party but wanted to give this a little bit more visibility as I have used a more bare-bones Jekyll beforehand.
Installation is simple via:
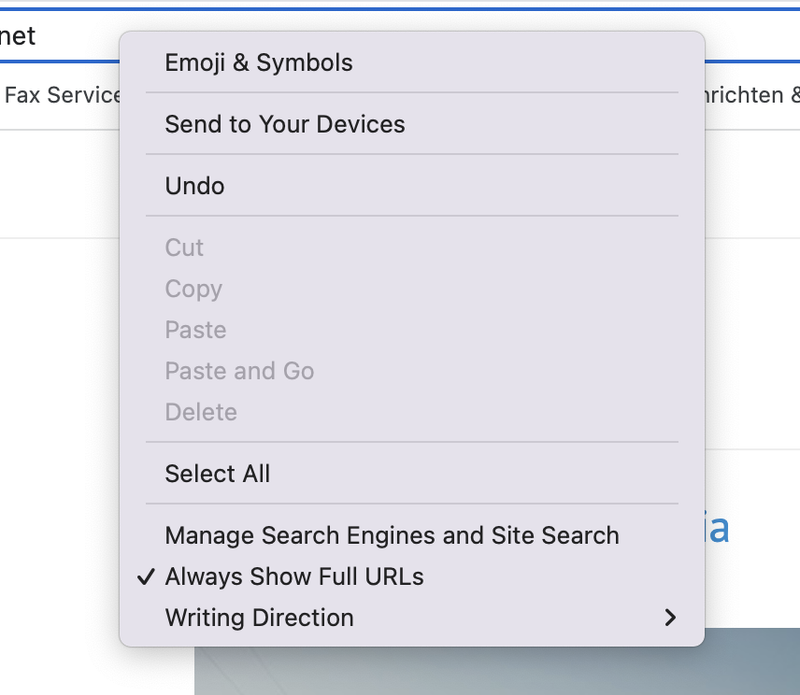
To show the full URL in Chrome, right click on the address bar and check “Always show full URLs”. This shows the http(s) portion of the URL in all cases and not only the domain name.